本文是对 Introduction to Information Retrieval第13章部分-Text classification and Naive Bayes 的阅读笔记. 同时参考了斯坦福大学自然语言处理第六课“文本分类(Text Classification)”这篇博客
文本分类
分类技术(Classification),顾名思义,就是按照预定义的类别,为数据集合中的数据记录进行自动分类标记的过程.当输入为一条待分类的记录 r 和一组固定的类别集合 C = {C 1 , C 2 , … , C j }时,分类技术对应的输出为记录 r 的预测类别 C i.常见的分类任务有:
- spam detection 垃圾过滤
- sentiment detection 情感分析
- personal email sorting 邮件分类
- topic-specific or vertical search 面向主题的搜索
分类问题的描述
我们用小写的字母来表示某个具体的文档或类别:用d表示一个文档,用c表示一个类别.对应的,我们用大写的字母表示文档或这类别的集合:用X表示所有文档的集合,C表示所有类别的集合,D表示训练集.
在训练集D中,包含了一系列已经被分类的文档<d,c>,其中\(<d,c>\in X \times C\). 比如<d,c>=<Beijing joins the World Trade Organization, China>
在分类问题中,我们目标是得到一个分类函数(classificaiton function),y. 从而利用这个y函数,将文档映射到对应的类别里:y:X->C.这个分类器y的参数需要通过对训练集的”学习”(learning)得到. 当文档的标签由人为定义, 训练集由人工标注的时候,我们称其为有监督的学习.
朴素贝叶斯分类器
我们介绍的第一个有监督的学习方法是朴素贝叶斯模型(Naive Bayes),号称”数据挖掘十大经典算法”之一, 有着简单直接的理论基础.
其名称中,”贝叶斯”指的是贝叶斯定理, 即后验概率正比于先验概率乘以条件概率. “朴素”二字的涵义是,模型中对条件概率分布坐了条件独立假设–”朴素”得假设各个文档特征(词Xi)在特定类别下,出现是概率是相互独立的.
(一) 分类过程
P(c|d)表示文档d属于某个类c的概率,则分类的过程等价于求c_MAP的过程,如下:
各个步骤说明如下:
- c_MAP即使得后验概率P(c|d)的类别
- 根据贝叶斯定理,后验概率P(c|d)转化为求先验概率P(c)和条件概率P(d|c)的问题
- 去分母
- 引入特征值,这里的特征是关键词
根据条件独立假设有: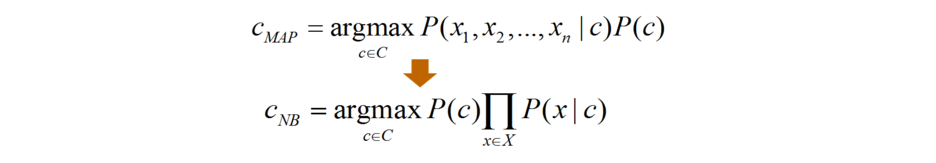
(二)学习的过程
在对新文档预测之前,需要先学习朴素贝叶斯模型,或称模型的参数估计。我们面对的主要任务就是估计p(c)和p(x|c)。最直接的方法就是在训练语料库基础上,用极大似然估计法(maximum likelihood estimates)估计相应的概率。
先验概率p(c)的极大似然估计是: 属于c_j的文档数, 占所有文档书的比例
根据条件概率p(x|c)的估计方法不同,又分为多项式模型和伯努利模型
多项式模型:
多项式模型考察关键词出现的频率, 特征是关键词,值是单词出现的次数. 条件概率p(x|c)的极大似然估计是:c类中所有文档里面关键词w出现的次数/c类中所有文档的总词数
伯努利模型:
伯努利模型考察关键词在各个文档中是否出现, 条件概率p(x|c)的极大似然估计是:c类中出现关键词w的文档数/c类中总共的文档数. 所以在伯努利模型中,关键词w在某一文档d中一旦出现,则出现1次还是出现10次的对分类结果没有影响.
平滑

举例
这里使用书上的两个例子,来比较多项式模型和伯努利模型的异同.
问题描述:
多项式模型:(其中+6为平滑. 6个关键词V={Chinese,Beijing,Shanghai,Macco,Tokyo,Japan})
伯努利模型:(其中+2为平滑. 2种状态{出现x/不出现x}